本稿では、Javaと独自フレームワークで構築された現行の教務システムをTypeScriptとNext.jsで構築された次世代教務システムへと移行していく過程で取り組んでいることを紹介していきます。
はじめに
こんにちは。N 高等学校 / S 高等学校の教務システム開発チームの邑本です。ドワンゴでは、N予備校のシステムだけでなくN高等学校とS高等学校の教務システムも開発しています。本稿では、今まであまり触れてこられなかったN高、S高の教務システムについてお話しようと思います。
現在、教務システムの開発チームでは、Javaで構築されている現行の教務システムからTypeScript/Next.jsベースの次世代教務システムへの移行を試みています。
現行の教務システムの機能は多岐に渡るため、
- 既存業務の見直しによる変更がある場合
- 新規で機能を開発する場合
に限って次世代教務システムで開発し、小さな改修は現行の教務システム上の変更に留めるという方針で移行を進めています。
その次世代教務システムへの移行案件第一弾が、2月の頭に無事リリースされたため、今回は次世代教務システムについて紹介させていただきます。
以後、簡単のため
- 現行の教務システム → v1
- 次世代教務システム → v2
と呼びます。
教務システムについて
そもそも教務システムとは何か
教務システムとは、学校を運営する上で発生する「校務」を管理するシステムです。 具体的には以下のような校務があります。
- 出願校務
- 出願から入学までの様々な手続き
- 生徒校務
- 履修登録
- 試験採点
- スクーリング
- 請求
- 成績
- 進級
- 卒業
全体アーキテクチャ
上述の通り、v1からv2へは機能単位での移行であるため、現状はv1とv2が以下の図のように共存しています。図からわかるように、N高とS高は同一のアプリケーションが別々に動いています。これは急務ではないが解決したい課題の一つです。
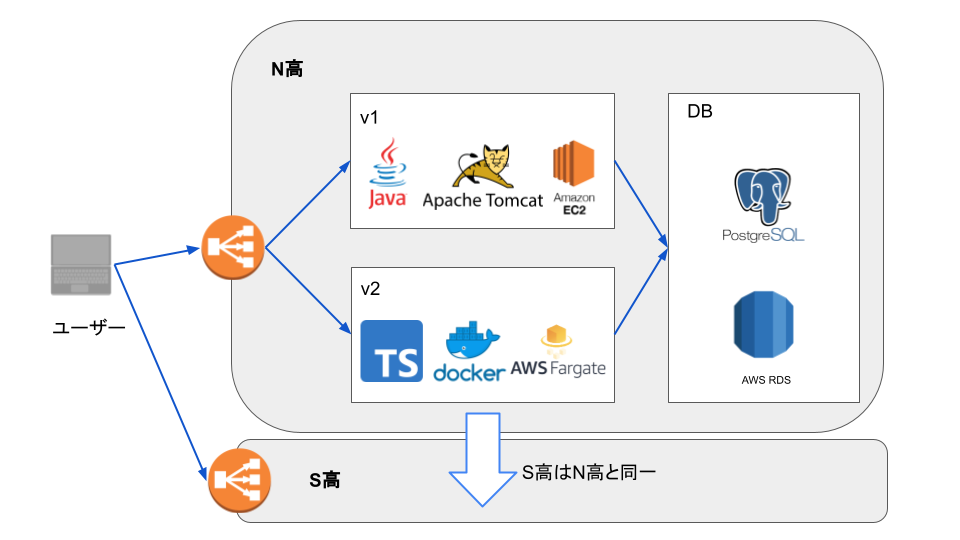
技術スタック
現行の教務システム
- 開発言語
- Java8
- JavaScript
- フレームワーク
- 独自フレームワーク(strutsベース)
- 実行環境
- AWS EC2
- CI/CD
- Jenkins
- 概要
- よくあるマルチページアプリケーション構成でFreeMarkerというテンプレートエンジンを使用してレンダリングしています。画面の動的制御にはjQueryを使用しています。
次世代教務システム
- 開発言語
- Typescript
- フレームワーク:
- Next.js
- Fastify
- 実行環境
- AWS ECS
- AWS Fargate
- CI/CD
- GitHub Actions
- 概要
- カスタムサーバー構成のフルスタックNext.jsで、Webサーバ部分にFastify、ORMにPrismaを使用しています。
共通
- データストア
- PostgreSQL
- モニタリング
- CloudWatch
- バージョン管理
- git
- GitHub Organization
- コミュニケーション
- Slack
- Jira
- Confluence
- G Suite
開発体制
- マネージャー1名
- アプリ開発者13名
- SRE2名
なぜ次世代教務システムが必要か
1. v1の歴史的経緯による技術的負債が溜まってきたため
v1は、他社が通信制高校向けに販売していた教務システムのパッケージが元になっています。N高やS高のように数万人規模の大規模なデータを取り扱うことは通信制高校では稀であるため、そこまで想定した作りになっておらず、追加開発にあたり開発体験があまり良くないため、v2が必要ということになりました。(パッケージソフトという性質上、変化に柔軟に対応するのが難しいのは尤もであり、当時の判断を責める意図はありません。)
2. よりリッチなUIによって業務効率を高める必要があるため
v1は、古典的なMPAで作られており、Form Submitとページ遷移の繰り返しが多いため、ユーザー体験が芳しくありませんでした。よりインタラクティブな操作による業務効率化を素早く実現するため、jQueryよりも簡単にリッチなUIを作ることのできる技術が必要がでした。
次世代教務システムの開発について
バックエンド
特に有名なアーキテクチャの採用などはしておらず、「ロジックとIOの分離」さえ守っていれば現状は問題ないという方針で開発しました。大事なのは変化に柔軟に対応できることであり、それは「ロジックとIOの分離」を守っていれば実現でき、アーキテクチャをどうするかという話は、開発者が増えて開発の規模が拡大し始めた段階で議論して決めていきたいと考えたからです。
フロントエンド
今回v2に追加した機能ではそれほど状態管理が複雑ではなかったため、バケツリレーで泥臭く実装しました。状態管理ライブラリの導入を検討した際、Recoilが簡単で便利そうだと思いましたが、まだ「experimental」の段階だったため見送りました。
インフラ・CI/CD
ドワンゴにはGitHub Enterpriseが導入されていますが、
- もともとのv1は普通のGitHubのプライベートリポジトリで管理されていた
- GitHub Actionsを使ってデプロイしたい(意思決定の段階ではEnterpriseでActionsを使う機構がなかった)
という2つの理由から教育事業本部のGitHub Organizationを作成し、普通のGitHubを使用していくことにしました。
現在、デプロイはGitHub Actions上で
ビルド => ECRにイメージをプッシュ => AWS Fargateで実行
という手順になっています。
次世代教務システムの開発で大変だったこと
カスタムサーバの導入
教務システムの開発では、1機能を任された開発者がバックもフロントも作ります。そのため、Blitz.jsのようなフルスタックNext.js構成を目指しました。(Blitz.jsはまだプロダクションレディではなかったので採用しませんでした。)しかし、
- 開発を始めた当初はまだNext.jsが10系であり、12系で追加されたmiddlewareの機能がなかったため、リクエスト時にログを書き込む処理や認証処理をページごとに書かざるを得ない
- Next.jsの「Api Routes」の機能が、if文でhttpメソッドごとの処理を記述する必要があるなどWebサーバ機能としてはものたりない
という理由から、Webサーバ機能を自前で実装するカスタムサーバ構成にしました。このカスタムサーバ部分にFastifyを用いています。
Fastifyのルーティング周りのバリデーション
Fastifyには、json schemaを指定することでリクエストのボディやパラメータをチェックし不正な値であればハンドラー(オブジェクト指向言語のFWで言うところのコントローラークラスに生えているパブリックメソッド)が呼ばれる前にエラーをクライアントに返せます。また、ルーティングメソッドにジェネリクスで型を指定することで、リクエストのボディやパラメータが型付けされ、ハンドラー内で手作業でパラメータやボディをパースする必要がなくなります。ここの実装では以下2つの難所がありました。
1. TSの型情報と実際に受け取った型が違う問題
はじめの頃、json schemaを指定しないと、パスパラメータを定義した型と実際にわたされた値の型が異なることに気づかずハマってしまいました。/foo/:hoge/barのようなエンドポイントに対し、hogeはnumber型と定義したため、もちろんトランスパイラは変数hogeをnumber型と推論します。私はこれでフレームワークが内部的にhogeをパースしてnumber型を渡してくれると思っていましたが、'1'のようにstringで渡されました。よく考えてみれば、TypeScriptの型は実行時に消失するので、ルーティングメソッドにジェネリクスで型を指定してリクエストのボディやパラメータに型付けをするのはasを使用するようなものなのだと理解しました。
type Request = { Params: { hoge: number }; } // /foo/* がルーティングされる const fooRoutes: FastifyRoutes = fastify => { fastify .route<Request>({ method: 'DELETE', url: '/:hoge/bar', handler: deleteHandler, onRequest: commandMiddleware, // schema: json schemaを指定 }); }; const deleteHandler = async (req, reply) => { // 型は通るが、schemaを定義していないので変数hogeの実態はstring型 const hoge: number = req.params.hoge await deleteByHoge(hoge); } const deleteByHoge = async (hoge: number) => { // 型は通るが、schemaを定義していないので変数hogeの実態はstring型 await database.hogeTable.delete({ // DBのカラムhogeはint型なのに変数hogeの実態がstring型のためランタイムエラー発生 where: { hoge } }) }
2. リクエストのボディやパラメータを定義する型とjson schemaの二重管理問題
「1」の問題を解消するために、json schemaを指定する必要がありますが、愚直にjson schemaを書くと、リクエストのボディやパラメータの内容をTSの型とjson schemaとでそれぞれ定義する、いわゆる2重管理の問題がでてきます。これを避けるために、本システムではzodというバリデーションライブラリでリクエストのボディやパラメータのスキーマを定義し、そのスキーマから型とjson schemaを生成するようにしました。
Prismaのコードが長くなりがちな問題
Prismaはライブラリの仕様上、以下のようにどうしてもコードが長くなってしまいます。 クエリに関しては妥協するとして、insertやupdateでデータを渡す際にスプレッド構文を用いてデータを渡そうとすると、存在しないプロパティは無視してほしいのですが、実際はエラーが発生してしまいました。 そのため、insertやupdateのときもカラムを列挙するためコードが長くなってしまっています。
async ({ hoge }) => { return table.findMany({ where: { hoge, hogehoge: null }, orderBy: [ { foo: { foofoo: 'asc', }, }, { bar: { barbar: 'asc', }, }, ], include: { children: { orderBy: [ { foo: { foofoo: 'asc', }, }, { bar: { barbar: 'asc', }, }, ], }, }, }); };
Ag Gridの学習コストや難点
Ag Gridとは、v2のフロントエンド開発を支える肝となる、グリッドテーブルを構築するコンポーネントライブラリです。Ag GridはリッチなグリッドUIを簡単に実現できるライブラリで、ドラッグ・アンド・ドロップやコピー・アンド・ペーストを実装したグリッドテーブルを比較的簡単に構築できます。大量のデータを取り扱うのを得意としており、フィルタやグルーピング機能など優れた機能が標準で搭載されています。このライブラリを使用するにあたって、以下のような課題がありました。
- Ag Gridは情報が少なく、あったとしてもAngularベースの情報が多く、苦労しました。公式ドキュメントはわかりやすいのですが、ドキュメント内検索してもヒットしないが提供されている関数や型があり、それを探すために補完の一覧を一つずつ見ていくなどして大変でした。
- Ag Gridから行のデータを受け取る際にデータがany型で渡されるのが悩みのタネでした。データを受け取るたびにType Guardの関数を呼んで条件分岐するのを避けるため、ここでは妥協してasを使いました。
- Ag Gridでは以下のサンプルコードのようにしてグリッドを構築します。このサンプルだと、ageカラムを更新すると更新された人の名前と年齢が一番上に表示されます。このコードの問題は、コピー・アンド・ペーストで複数行を一気に更新すると
onCellValueChangedが行数分実行されることです。setNameとsetAgeが呼ばれると再レンダリングが走るため、複数行分onCellValueChangedが実行されると画面が非常に重たくカクついてしまいました。最初これに気づかず、計算量の問題かと思いメモ化するなど、さまざまな工夫をするも解消せず、かなりハマりました。最終的には、useDebounceというライブラリとuseRefを使い、状態は関数が更新されるたびに更新しつつ、再レンダリングを伴う処理をする関数は一定時間内に何度呼ばれても一回だけ走るようにして解決しました。
const Grid = () => { const [name, setName] = useState() const [age, setAge] = useState() return ( <> あなたは直前で{name}さんの年齢カラムを{age}歳に修正しました。 <AgGrid> <AgGridColumn field={'name'} /> <AgGridColumn field={'age'} onCellValueChanged={({data}) => { setName(data.name) setAge(data.age) }} /> </AgGrid> </> ) }
次世代教務システムで取り組んでよかったこと
部分的なテスト駆動開発
今回の機能追加では、フロントエンドでの自動計算が多かったため、フロントエンドの計算ロジックに対してはテストコードを書いていました。おかげで品質保証チームから起票されたバグへの対応や後から追加された仕様に対して迅速に対応できました。
再代入の局所化
基本的に「constで変数宣言し、letで宣言して再代入を許容するのはライフタイムがローカルスコープ内で完結する変数のみとする」という方針でコーディングすることでコードの見通しが良くなり、開発速度の向上に繋がりました。
v2で具体的には何が改善されたのか
ここまで技術の話がメインでしたが、最後に、「v1からv2への移行で具体的には何が改善されたのか」を実際に移行した機能の移行前と移行後の画面を比較して紹介します。
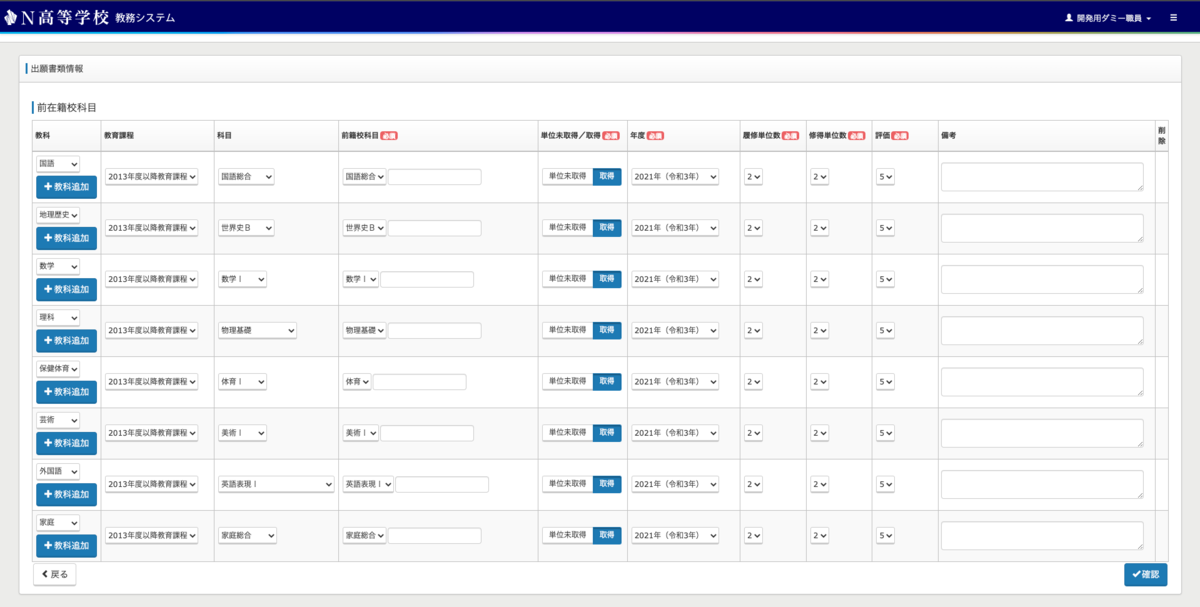
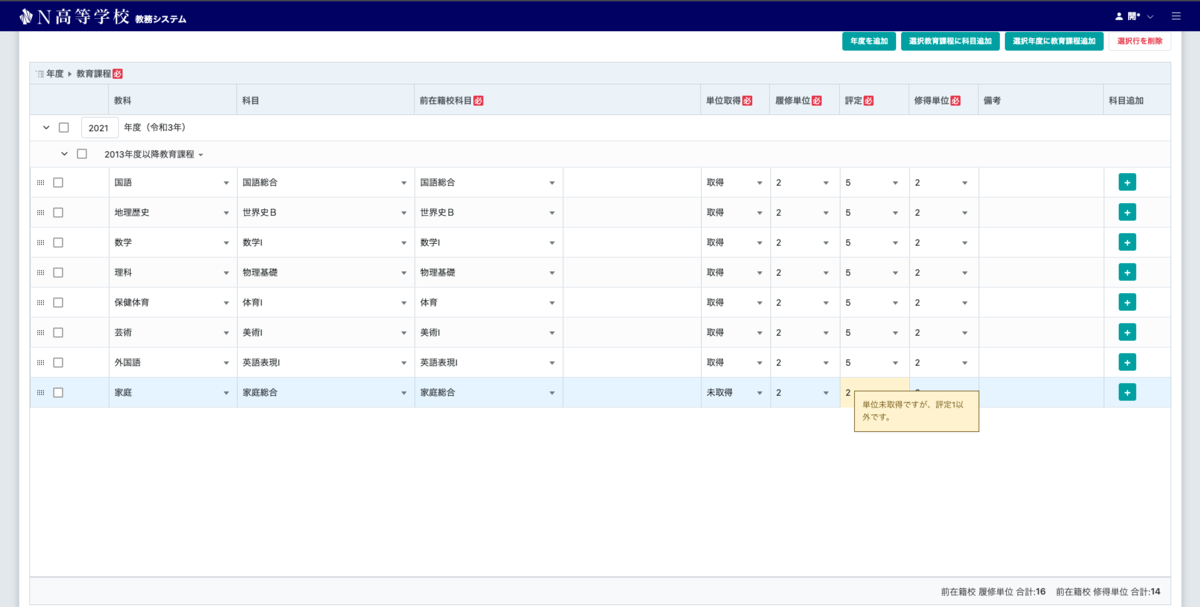
- 以下のv1画像は全編集画面という、編集しかできない画面です。v1では新規作成と編集のフローが別れていたのをv2では同一のページで行えるようになりました。
- v1では、新規作成時に年度や教育課程など同一の内容を複数回選択する必要がありました。v2では年度と教育課程でグルーピングし、グループ行を編集する形式に変更することで作業効率アップを実現しています。
- 画面からは読み取れませんが、v1はある行とほとんど同じ内容で1カラムだけ変更すれば良いデータでも、登録するためには全カラムを1つずつ入力する必要がありました。v2では行をコピーして貼り付けられるようになり、単純作業の大幅な削減ができました。
- v1では警告文やエラー文を項目をすべて入力後に確認画面へ遷移したのち、項目確認のための一覧テーブルの上部にアラートで表示させていました。一方v2では、警告文やエラー文を該当箇所にツールチップで表示するようにしました。結果として、アラートの文を読んで該当箇所を探すという視線の上下がなくなり、かつ、編集画面に戻ってから再編集し、再び確認画面へ遷移する手間を削減できました。
v1
v2
今後の展望
テスト駆動開発の文化醸成
納期の都合上、今回はフロントエンドの方にロジックが寄っていたため、バックエンドはテストコードを書かず、品質保証チームのテスト任せになってしまっていました。そして本番稼働後、(幸いバグ報告は一件もありませんが)後追いでテストコードを拡充しているのが現状です。
- 本来であれば、どちらかといえばバックエンドをユニットテスト必須にするのが正だと思う
- フロントの自動計算部分でテストコードを書いて、テスト駆動の恩恵はよくわかっているため、v2の開発チームではできる限りテスト駆動で開発する文化を作っていきたいと思います。
認証基盤の統一
先述の全体アーキテクチャ図からわかるように、現在N高とS高の教務システムはそれぞれログインが必要です。これはユーザー体験を損ねてしまっているため、いずれは統合し、ヘッダーで操作する学校を切り替えられるようにしたいと考えています。
We are hiring!
株式会社ドワンゴの教育事業では、一緒に未来の当たり前の教育をつくるメンバーを募集しています。 カジュアル面談も行っています。 お気軽にご連絡ください!
開発チームの取り組み、教育事業の今後については、他の記事や採用資料をご覧ください。